Error reduction and model accuracy in machine learning are some vital objectives. One way to get this done is through ensemble methods, which merge predictions from several different models to generate a powerful and accurate final model. It is better to depend on the intelligence of multiple models rather than using the prediction of a single model. Ensemble techniques utilize this collective intelligence to predict the final model.
The most popular ensemble techniques are Bagging, or Bootstrap Aggregating, and Boosting. Though these two models have the same aim, their methods to improve model performance vary deeply from each other. Bagging trains several independent models to decrease radiance, while boosting trains models sequentially to decrease bias, in which each model learns from the mistakes of its predecessors.
In this blog, I will be explaining their definitions, how each of them works, the steps of bagging and boosting, the advantages of the two, and some other important aspects.
Bagging: Definition
Bagging or Bootstrap Aggregating is an ML ensemble meta-algorithm developed to enhance the stability and accuracy of machine learning algorithms. These ML algorithms are used in statistical classification and regression. Bagging helps to prevent overfitting and also decreases the variance. Mostly, it is relevant in decision tree methods. This technique is a special case of the model averaging approach.
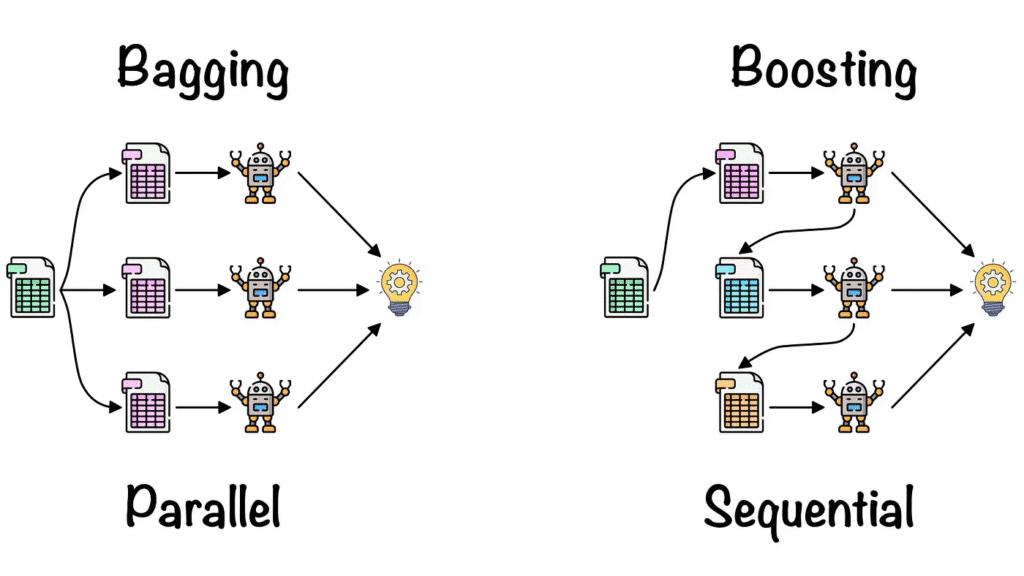
How Bagging Works?
It generates several bootstrapped datasets and trains a different model on each of these datasets. The idea behind this is that by collecting predictions from each of the models (trained on similar datasets), the variance of the models decreases, resulting in the most accurate and trustworthy final predictions.
Bagging Steps:
- The first step is data sampling, which involves the development of several subsets of the original dataset by using bootstrapping. Each of the subsets might have duplicate instances, but they will be varied in nature from the others.
- The second step is model training; every bootstrapped subset of the data is used to train a separate model. Mostly, these models are of the same type, like decision trees, but each of them sees different data.
- The final step involves classification tasks, where a majority vote is taken across all models to make the final prediction. It is the average of all the models’ predictions.
Advantages of Bagging in Machine Learning
- As bagging requires averaging several predictions, it decreases variance in the model and prevents overfitting.
- By combining multiple models, the performance is enhanced rather than depending on individual models.
- Models trained on bootstrapped datasets are less influenced by noise or outliers in the data.
- It allows easy parallelization, which fastens training based on the availability of resources.
Bagging Example
One of the most well-known bagging examples is the Random Forest model. Higher variance decision tree models are present. It uses random feature selection to grow trees, and multiple random trees make a Random Forest.
Boosting: Definition
It is an ensemble modeling technique developed to build a powerful classifier by merging several weak classifiers. In the boosting process, models are built sequentially, where every new model proceeds to correct the mistakes made by its previous model. Boosting is more focused on decreasing bias than variance, like bagging.
How Boosting Works?
It works by developing one model at a time, with each model focusing on reducing the mistakes of its predecessor. Boosting functions on the concept of learning from past mistakes and improving gradually over time.
Boosting Steps:
- The first step is model initialization, where a weak learner (like a decision tree) is trained on the entire dataset.
- In the weight adjustment step, the algorithm allocates the higher weights to the incorrectly classified examples. It accentuates them in the training’s next round. This makes sure that the next model focuses on these hard examples.
- Now comes the model combination in which each model is added to the ensemble, and its prediction is merged with that of the others. In classification, a weighted majority voting is used. And for regression, all the predictions from the models are averaged.
Advantages of Bagging in Machine Learning
- Boosting decreases bias and enhances the overall accuracy of the model by focusing on hard-to-classify instances.
- Merging weak learners results in a strong predictive model.
Boosting Example
There are several examples of boosting algorithms, like AdaBoost, developed by Robert Schapire and Yoav Freund. It had won the very honorable Gödel Prize. Boosting was developed for binary classification and is the short form of Adaptive Boosting. It merges several weak classifiers into one strong classifier.
Some other notable bloating examples include:
- Gradient Boosting Machines (GBM), popularly used in predictive analytics tasks such as sales forecasting, customer churning, and speculating credit default risks.
- XGBoost (Extreme Gradient Boosting), used in data science competitions, time-series forecasting, marketing analytics, etc.
- LightGBM (Light Gradient Boosting Machine), used in large-scale ML tasks like classification, ranking, regression, etc.
Also Read: Top Robotics Companies That Will Lead the Market in 2026
How are Bagging & Boosting Similar to Each Other?
While bagging and boosting are distinctive ensemble techniques that have separate approaches, they are also more similar than you might think. Let’s take a look at some of their similarities that make them effective for model performance improvement.
- Both bagging and boosting come under ensemble techniques, which merge the predictions of several models to develop a powerful and accurate finished model. By merging multiple weak learners, the final ensemble model will have enhanced performance over any individual model.
- The unified goal of bagging and boosting is to enhance the machine learning model’s performance by minimizing errors that occur in a single model. In both cases, overfitting is reduced by combining multiple models, which leads to improved generalization to unseen data.
- Both bagging and boosting enhance the performance of base learners, which, when combined, create a powerful overall model.
- Both these ensemble techniques can be applied to a variety of ML tasks, like classification and regression. These techniques are fluid enough to be used with different base learners, depending on the particular problems being solved.
Difference Between Bagging & Boosting
After knowing the similarities, you must be intrigued to learn about the differences between these two ensemble techniques. Let’s check out some differences in various aspects.
| Feature | Bagging | Boosting |
| Aim | Averages predictions across several models to minimize variance | Learns sequentially from model mistakes to reduce bias |
| Model Training | Independent model training on varied data subsets | Sequential training of models to make them learn from the errors of their predecessors |
| Data Sampling | Uses bootstrapped datasets | Uses the entire dataset, no bootstrapping |
| Model Combination | Voting for classification and averaging for regression | Based on performance, the models’ weighted combination |
| Overfitting Risk | Less like of overfitting | Increased risk of overfitting in the case of a complex model |
| Focus | Enhancing stability and minimizing variance | Enhancing accuracy by minimizing bias |
| Model Diversity | Models are mostly diverse due to bootstrapping and are trained in parallel | Sequential training of models |
| Computational Efficiency | Efficient computationally due to parallelization. | Computationally intensive due to sequential training |
| Base Learner | Mostly uses efficient learners like decision trees | Mostly uses weak learners like shallow decision trees |
| Use Case | Used in minimizing overfitting in high variance models | Suitable for enhancing model accuracy on complex datasets |
| Well-Known Algorithms | Bagging Classifier, Random Forest | AdaBoost, Gradient Boosting Machines |
In Conclusion
Bagging and boosting are two essential ensemble techniques that you must understand and effectively use to enhance the power and performance of machine learning models. Data scientists utilize the bagging and boosting techniques to improve their machine learning models’ accuracy and reliability.
Ensemble learning, including bagging and boosting, is an essential tool in machine learning. As already discussed, bagging minimizes variance by averaging multiple models, whereas boosting sequentially enhances predictions by learning from past errors. If you are handling classification or regression issues, utilizing these two techniques strategically will lead to more accurate predictive models. As a result, it can be used to achieve improved decision-making and insights across various real-world applications.
Must Read: AI & Common Sense, Will This Union Ever Be Possible?
Read More: What Is Data Collection? Methods, Challenges, Post-Processes, and Tools